![]()
|
|
|
|
FgenesB-Annotator |
To identify protein and RNA genes in bacterial genomic sequences or environmental samples, Softberry developed Fgenesb_annotator pipeline that provides completely automatic, comprehensive annotation of bacterial sequences. The pipeline includes protein, tRNA and rRNA genes identification, finds potential promoters, terminators and operon units.
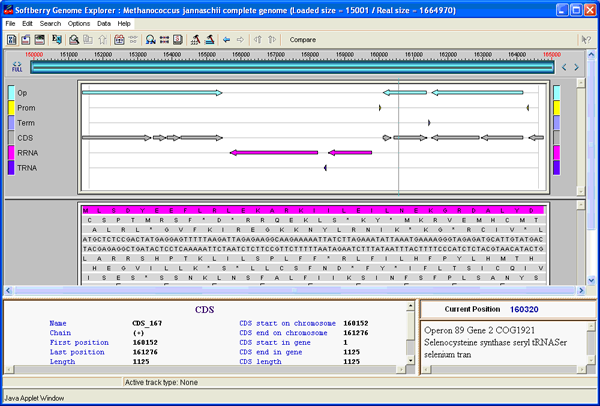
Predicted genes are annotated based on comparison with known proteins. The package provides options to work with a set of sequences such as scaffolds of bacterial genomes or short reads of DNA extracted from a bacterial community. The final annotation can be presented in GenBank form to be readable by visualization software such as Artemis [1] and GenomeExplorer (fig. 1 and 2). The gene prediction algorithm is based on Markov chain models of coding regions and translation and termination sites. For annotation of mixed bacterial community, we use special parameters of gene prediction computed based on a large set of known bacterial sequences. Operon models are based on distances between ORFs, frequencies of different genes neighboring each other in known bacterial genomes, and information from predicted potential promoters and terminators. The parameters of gene prediction are automatically trained during initial steps of sequence analysis, so the only input necessary for annotation of a new genome is its sequence. Optionally, parameters from closely related genomes can be used, instead of training new parameters. Bacterial gene/operon prediction and annotation requires, besides Fgenesb_annotator programs and scripts, BLAST, NCBI Non-Redundant database (NR), and a file reconstructed from COG database [2]. RRNA genes are annotated using BLAST similarity with all known bacterial rRNA database. For prediction of tRNA genes, the pipeline uses tRNAscan-SE package [3].
1. K. Rutherford, J. Parkhill, J. Crook, T. Horsnell, P. Rice, M-A. Rajandream and B. Barrell (2000) Artemis: sequence visualisation and annotation. Bioinformatics 16 (10) 944-945.
2. Tatusov RL, Natale DA, Garkavtsev IV, Tatusova TA, Shankavaram UT, Rao BS, Kiryutin B, Galperin MY, Fedorova ND, Koonin EV. (2001) The COG database: new developments in phylogenetic classification of proteins from complete genomes. Nucleic Acids Res. 29, 22-28.
3. Lowe, T.M. & Eddy, S.R. (1997) "tRNAscan-SE: A program for improved detection of transfer RNA genes in genomic sequence", Nucl. Acids Res., 25, 955-964.
The package includes options to work with a set of sequences such as scaffolds of bacterial genomes, or short sequencing reads extracted from bacterial communities. For community sequence annotation, we developed ABsplit program that separates archaebacterial and eubacterial sequences (available separately). Final annotation can be presented in GenBank format to be readable by visualization software such as Artemis or Softberry Bacterial Genome Explorer (fig. 1 and 2, GenBank parser is available separately).
Many steps are optional and can be switched ON/OFF in configuration file.
STEP 1. Finds all potential ribosomal RNA genes using BLAST against bacterial and/or archaeal rRNA databases, and masks detected rRNA genes.
STEP 2. Predicts tRNA genes using tRNAscan-SE program (Washington University) and masks detected tRNA genes.
STEP 3. Initial predictions of long ORFs that are used as a starting point for calculating parameters for gene prediction. Iterates until stabilizes. Generates parameters such as 5th-order in-frame Markov chains for coding regions, 2nd-order Markov models for region around start codon and upstream RBS site, stop codon and probability distributions of ORF lengths.
STEP 4. Predicts operons based only on distances between predicted genes.
STEP 5. Runs BLAST for predicted proteins against COG database, cog.pro.
STEP 6. Finds conserved operonic pairs from blast output through cog data.
STEP 7. Uses information about conservation of neighboring gene pairs in known genomes to improve operon prediction.
STEP 8. Runs BLAST for predicted proteins against KEGG database.
STEP 9. Runs BLAST for predicted proteins against NR database.
STEP 10. Adds names of homologs from COG/KEGG/NR (found through BLAST) to annotation file (file with prediction results).
STEP 11. Predicts potential promoters (BPROM program) or terminators (BTERM) in upstream and downstream regions, correspondingly, of predicted genes. BTERM is the program predicting bacterial-independent terminators with energy scoring based on discriminant function of hairpin elements.
STEP 12. Refines operon predictions using predicted promoters and terminators as additional evidences.
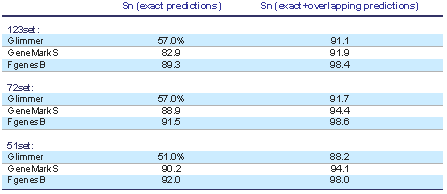
FGENESB gene prediction engine is one of the most accurate prokaryotic gene finders available: see Table 1 for its comparison with two other popular gene prediction programs.
Table 1. Comparison of three popular bacterial gene finders. Accuracy estimate was done on a set of difficult short genes that was previously used for evaluating other bacterial gene finders (http://opal.biology.gatech.edu/GeneMark/genemarks.cgi). First set (51set) has 51 genes with at least 10 strong similarities to known proteins. Then 72set has 72 genes with at least two strong similarities, and 123set has 123 genes with at least one protein homolog. Here are the prediction results on these three sets for GeneMarkS and Glimmer (calculated by Besemer et al. (2001) Nucl. Acids Res. 29:2607-2618) and FGENESB gene prediction engine (calculated by Softberry).
All prediction components of FGENESB are extremely fast (minutes per genome). The limiting stage is BLAST annotation, which for E.coli genome takes around 12 hours on a single processor. Using multiple processors and corresponding BLAST would speed up annotation proportionally.
Example of FGENESB output:
Prediction of potential genes in microbial genomes
Time: Tue Aug 22 11:21:15 2006
Seq name: gi|15807672|ref|NC_001264.1| Deinococcus radiodurans R1 (partial sequence)
Length of sequence - 54865 bp
Number of predicted genes - 48, with homology - 48
Number of transcription units - 18, operons - 13 average op.length - 3.3
N Tu/Op Conserved S Start End Score
pairs(N/Pv)
- TRNA 147 - 222 78.9 # Arg CCG 0 0
+ TRNA 315 - 398 63.6 # Leu TAG 0 0
+ 5S_RRNA 521 - 637 100.0 # AB001721 [D:2735..2851]
+ SSU_RRNA 698 - 2181 100.0 # SSU_RRNA ##
+ LSU_RRNA 2302 - 5345 100.0 # BX248583 [R:613128..616171]
+ Prom 5304 - 5363 41.4
1 1 Op 1 22/0.000 + CDS 5410 - 6300 498 ## COG1192 ATPases involved �
2 1 Op 2 . + CDS 6297 - 7178 502 ## COG1475 Predicted �
+ Term 7203 - 7253 9.1
- Term 7191 - 7241 14.2
3 2 Tu 1 . - CDS 7283 - 8746 909 ## COG1012 NAD-dependent �
- Prom 8792 - 8851 2.8
4 3 Tu 1 . + CDS 8802 - 9533 302 ## COG2068 Uncharacterized �
+ Term 9779 - 9818 3.8
- Term 9527 - 9567 9.0
5 4 Op 1 2/0.125 - CDS 9584 - 10762 1005 ## COG1063 Threonine �
6 4 Op 2 . - CDS 10759 - 11457 666 ## COG5637 Predicted integral �
- Prom 11697 - 11756 2.4
7 5 Op 1 37/0.000 + CDS 11704 - 12609 872 ## COG1131 ABC-type multidrug �
8 5 Op 2 5/0.000 + CDS 12726 - 13517 812 ## COG0842 ABC-type multidrug �
9 5 Op 3 15/0.000 + CDS 13674 - 14684 1028 ## COG4585 Signal transduction �
10 5 Op 4 . + CDS 14681 - 15316 506 ## COG2197 Response regulator �
�
47 18 Op 1 . - CDS 53783 - 54703 431 ## DRA0045 hypothetical �
48 18 Op 2 . - CDS 54700 - 54864 91 ## DRA0046 hypothetical �
Predicted protein(s)
>gi|15807672|ref|NC_001264.1| GENE 1 5410 - 6300 498 296 aa, chain + ## HITS:3 COG:DRA0001 KEGG:FRAAL2247 NR:6460595 ## COG: DRA0001 COG1192 # Protein_GI_number: 15807673 # Func_class: D Cell cycle control, cell division, chromosome partitioning # Function: ATPases involved in chromosome partitioning # Organism: Deinococcus radiodurans # 37 296 1 260 260 459 100.0 1e-129 ## KEGG: FRAAL2247 # Name: not_defined # Def: chromosome partitioning protein (partial match) [EC:2.7.10.2] # Organism: F.alni # Pathway: not_defined # 48 283 50 291 302 118 35.0 5e-26 ## NR: gi|6460595|gb|AAF12301.1| chromosome partitioning ATPase, putative, ParA family [Deinococcus radiodurans R1]^Agi|15807673|ref|NP_285325.1| chromosome partitioning ATPase, putative, ParA family [Deinococcus radiodurans R1] # 37 296 1 260 260 459 100.0 1e-128
VLKNHLFLRNLIFSVLPVVQHFLTFKEEQSIADLSDMVSAVKTLTVFNHAGGAGKTSLTL
NVGYELARGGLRVLLLDLDPQANLTGWLGISGVTREMTVYPVAVDGQPLPSPVKAFGLDV
IPAHVSLAVAEGQMMGRVGAQGRLRRALAEVSGDYDVALIDSPPSLGQLAILAALAADQM
IVPVPTRQKGLDALPGLQGALTEYREVRPDLTVALYVPTFYDARRRHDQEVLADLKAHLS
PLARPVPQREAVWLDSTAQGAPVSEYAPGTPVHADVQRLTADIAAAIGVAYPGENA
>gi|15807672|ref|NC_001264.1| GENE 2 6297 - 7178 502 293 aa, chain + ## HITS:3 COG:DRA0002 KEGG:SAR11_0354 NR:12230476 ## COG: DRA0002 COG1475 # Protein_GI_number: 15807674 # Func_class: K Transcription # Function: Predicted transcriptional regulators # Organism: Deinococcus radiodurans # 1 293 1 293 293 478 100.0 1e-135 ## KEGG:
SAR11_0354 # Name: parB # Def: chromosome partitioning protein [EC:2.7.7.-] # Organism: P.ubique # Pathway: not_defined # 10 200 12 177 282 107 36.0 7e-23 ## NR: gi|12230476|sp|Q9RZE7|PARB2_DEIRA Probable chromosome 2 partitioning protein parB (Probable chromosome II partitioning protein parB)^Agi|6460594|gb|AAF12300.1| chromosome partitioning protein, ParB family [Deinococcus radiodurans R1]^Agi|15807674|ref|NP_285326.1| chromosome partitioning protein, ParB family [Deinococcus radiodurans R1] # 1 293 1 293 293 478 100.0 1e-133
MTRRRPERRRDLLGLLGETPVDLSQANDIRALPVNELKVGSTQPRRSFDLERLSELAESI
RAHGVLQPLLVRSVDGQYEIVAGERRWRAAQLAGLAEVPVVVRQLSNEQARAAALIENLQ
RDNLNVIDEVDGKLELIALTLGLEREEARKRLMQLLRAVPGDEHEQLDQVFRSMGETWRT
FAKNKLRILNWPQPVLEALRAGLPLTLGSVVASAPPERQAELLKLAQNGASRSQLLQALQ
TPSQTSAVTPEHFAKVLSSKRFLSGLDTPTREALDRWLARMPERVRQAIDEQS
...
Example of FGENESB output in GenBank format (scripts run_tgb.pl, togenbank.pl):
gene complement(147..222)
/gene="Arg CCG"
tRNA complement(147..222)
/gene="Arg CCG"
/product="tRNA-Arg"
/note="Arg CCG 0 0"
gene 315..398
/gene="Leu TAG"
tRNA 315..398
/gene="Leu TAG"
/product="tRNA-Leu"
/note="Leu TAG 0 0"
gene 521..637
/gene="AB001721 [D:2735..2851]"
rRNA 521..637
/gene="AB001721 [D:2735..2851]"
/product="5S ribosomal RNA"
/note="AB001721 [D:2735..2851]"
gene 698..2181
/gene="SSU_RRNA"
rRNA 698..2181
/gene="SSU_RRNA"
/product="16S ribosomal RNA"
/note="SSU_RRNA"
gene 2302..5345
/gene="BX248583 [R:613128..616171]"
rRNA 2302..5345
/gene="BX248583 [R:613128..616171]"
/product="23S ribosomal RNA"
/note="BX248583 [R:613128..616171]"
promoter 5304..5363
CDS 5410..6300
/function="ATPases involved in chromosome partitioning"
/note="Operon 1 Gene 1 COG1192 ATPases involved in
chromosome partitioning"
/translation="VLKNHLFLRNLIFSVLPVVQHFLTFKEEQSIADLSDMVSAVKTL
TVFNHAGGAGKTSLTLNVGYELARGGLRVLLLDLDPQANLTGWLGISGVTREMTVYPV
AVDGQPLPSPVKAFGLDVIPAHVSLAVAEGQMMGRVGAQGRLRRALAEVSGDYDVALI
DSPPSLGQLAILAALAADQMIVPVPTRQKGLDALPGLQGALTEYREVRPDLTVALYVP
TFYDARRRHDQEVLADLKAHLSPLARPVPQREAVWLDSTAQGAPVSEYAPGTPVHADV
QRLTADIAAAIGVAYPGENA"
/transl_table=11
CDS 6297..7178
/function="Predicted transcriptional regulators"
/note="Operon 1 Gene 2 COG1475 Predicted transcriptional
regulators"
/translation="MTRRRPERRRDLLGLLGETPVDLSQANDIRALPVNELKVGSTQP
RRSFDLERLSELAESIRAHGVLQPLLVRSVDGQYEIVAGERRWRAAQLAGLAEVPVVV
RQLSNEQARAAALIENLQRDNLNVIDEVDGKLELIALTLGLEREEARKRLMQLLRAVP
GDEHEQLDQVFRSMGETWRTFAKNKLRILNWPQPVLEALRAGLPLTLGSVVASAPPER
QAELLKLAQNGASRSQLLQALQTPSQTSAVTPEHFAKVLSSKRFLSGLDTPTREALDR
WLARMPERVRQAIDEQS"
/transl_table=11
terminator 7203..7253
terminator complement(7191..7241)
CDS complement(7283..8746)
/function="NAD-dependent aldehyde dehydrogenases"
/note="Operon 2 Gene 1 COG1012 NAD-dependent aldehyde
dehydrogenases"
/translation="MTTTDLRTTYSSVTRSQAYFDGEWRNAPRNFEVRHPGNGEVIGE
VADCTPTDARQAIDAAEVALREWRQVNPYERGKILRRWHDLMFEHKEELAQLMTLEMG
KPISETRGEVHYAASFIEWCAEEAGRIAGERINLRFPHKRGLTISEPVGIVYAVTPWN
FPAGMITRKAAPALAAGCVMILKPAELSPMTALYLTELWLKAGGPANTFQVLPTNDAS
ALTQPFMNDSRVRKLTFTGSTEVGRLLYQQAAGTIKRVSLELGGHAPFLVFDDADLER
AASEVVASKFRNSGQTCVCTNRVYVQRGVAEEFIRLLTEKTAALQLGDPFDEATQVGP
VVEQAGLDKVQRQVQDALTKGAQATTGGQVSSGLFFQPTVLVDVAPDSLILREETFGP
VAPVTIFDTEEEGLRLANDSEYGLAAYAYTRDLGRAFRIAEGLEYGIVGINDGLPSSA
APHVPFGGMKNSGVGREGGHWGLEEYLETKFVSLGLS"
/transl_table=11
promoter complement(8792..8851)
...
BASE COUNT 11009 a 16099 c 16880 g 10877 t
ORIGIN
1 tctttgctcg ccatacccaa agtctacacg ctgattttca cgtttccaga ccctgccctc
61 tcgctactca gctctccaag tttgctcgct tgatgaatga tcaaatcttt taaagataaa
121 agccatgcgt gaggctagat caacccttgt gcccccggca ggattcgaac ctgcggcctt
...
54841 gtcgcccagt tgaatggctc gccac
//
Example of FGENESB output in Sequin format:
>Feature test_seq
222 147 gene
locus_tag C8J_0001
222 147 tRNA
product tRNA-Arg
inference profile:tRNAscan-SE:1.23
315 398 gene
locus_tag C8J_0002
315 398 tRNA
product tRNA-Leu
inference profile:tRNAscan-SE:1.23
521 637 gene
locus_tag C8J_0003
521 637 rRNA
product 5S ribosomal RNA
698 2181 gene
locus_tag C8J_0004
698 2181 rRNA
product 16S ribosomal RNA
2302 5345 gene
locus_tag C8J_0005
2302 5345 rRNA
product 23S ribosomal RNA
5304 6300 gene
locus_tag C8J_0006
5304 5363 promoter
5410 6300 CDS
product hypothetical protein
note similar to D.radiodurans chromosome partitioning ATPase �
protein_id gnl|bbsrc|C8J_0006
inference ab initio prediction:Fgenesb:2.0
6297 7253 gene
locus_tag C8J_0007
6297 7178 CDS
product chromosome partitioning protein, ParB family
protein_id gnl|bbsrc|C8J_0007
inference ab initio prediction:Fgenesb:2.0
7203 7253 terminator
8851 7191 gene
locus_tag C8J_0008
7241 7191 terminator
8746 7283 CDS
product succinate-semialdehyde dehydrogenase
EC_number 1.2.1.16
protein_id gnl|bbsrc|C8J_0008
inference ab initio prediction:Fgenesb:2.0
8851 8792 promoter
...
For each genomic sequence (complete genome, scaffold, read, etc.) the program lists locations of predicted ORFs, rRNAs, tRNAs, promoters and terminators.
ORFs are labeled as CDS and provided with their order number in a sequence and an indicator of whether they are transcribed as a single transcription unit (Tu) or in operons (Op) (of course these are predictions).
If an ORF has a homolog, its short name is provided after a "##" separator (here name of only
one homolog - either from COG, KEGG, or NR - is given; best homologs from all databases are listed in ID lines of predicted proteins, see below).
For example:
5 4 Op 2 + CDS 2737 - 3744 871 ## COG0673 Predicted dehydrogenases
is description for predicted gene number 5 in 4th Operon with coordinates 2737 - 3744 in the '+' strand and it is the second gene in operon.
Coding chain for this CDS (+) means a direct chain, (-) means a complementary chain. 871 is a score of gene homology assigned by BLAST, and COG0673 is an ID of its homolog from the COG database.
In other words, first column lists an ordered number of predicted CDS, starting from beginning of a sequence; second column - number of predicted operon/TU, and fourth column - number of gene in an operon (always 1 for a TU).
For some operons, we report supportive evidence related to conservation in relative locations of genes in predicted operon in different bacteria. For example:
3 2 Op 1 4/0.002 + CDS 3193 - 3405 278 ## COG2501 Uncharacterized ACR
Here, in 4/0.002, 4 is a number of observations of this gene being next to one of its neighbors on known bacterial genomes (we call it N-value), while 0.002 is a P-value, an empirical probability of observing N occurrences of genes being adjacent by random chance. P is a very approximate measure. For all P<0.0001, the value in output is 0.000.
At the end of annotation, we also provide protein products of predicted genes in fasta format, with full name of homolog and homology scores according to BLAST.
Information about homologs is given in ID lines of predicted proteins, for example:
>gi|15807672|ref|NC_001264.1| GENE 7 11704 - 12609 872 301 aa, chain + ## HITS:3 COG:DRA0007 KEGG:DRA0007 NR:6460585 ## COG: DRA0007 COG1131 # Protein_GI_number: 15807679 # Func_class: V Defense mechanisms # Function: ABC-type mult idrug transport system, ATPase component # Organism: Deinococcus radiodurans # 1 301 1 301 301 503 100.0 1e-142 ## KEGG: DRA0007 # Name: not_defined # Def: putative ABC-2 type transport system ATP-binding protein # Organism: D.radiodurans # Pathway: ABC transporters - General [PATH:dra02010] # 1 301 1 301 301 503 100.0 1e-142 ## NR: gi|6460585|gb|AAF12291.1| ABC transporter, ATP-binding protein, putative [Deinococcus radiodurans R1]^Agi|15807679|ref|NP_285331.1| ABC transporter, ATP-binding protein, putative [Deinococcus radiodurans R1] # 1 301 1 301 301 503 100.0 1e-141 MITTFEQVSKTYGHVTALSDFNLTLRTGELTALLGPNGAGKSTAIGLLLGLSAPSAGQVR VLGADPRRNDVRARIGAMPQESALPAGLTVREAVTLFASFYPAPLGVDEALALADLGPVA GRRAAQLSGGQKRRLAFALAVVGDPELLLIDEPTTGMDAQSRAAFWEAVTGLRARGRTIL LTTHYLEEAERTADRVVVMNGGRILADDTPQGLRSGVGGARVSFVSDLVQAELERLPGVS AVQVDAAGRADLRTSVPEALLAALIGSGTTFSDLEVRRATLEEAYLQLTGPQDMTAVTRS A
While looking a bit complex for a human eye, it is well suited for parsing by a program.
ID lines of predicted proteins consist of the following parts that are separated from each
other by "##" separator:
>gi|15807672|ref|NC_001264.1| GENE 7 11704 - 12609 872 301 aa, chain +
(sequence name, gene number, coordinates of a gene, length of a corresponding protein, chain)
## HITS:3 COG:DRA0007 KEGG:DRA0007 NR:6460585
(shows the number of homologs found in protein databases (takes into account maximum one best homolog per a database), lists homologs IDs in the format DB:ID (e.g., COG:DRA0007);
notes:
- for homologs from NR, gi- numbers are given as homologs IDs;
- DB:ns indicates that a protein DB was not searched (e.g., NR:ns);
- DB:no indicates that a protein DB was searched but no homologs were found (e.g., NR:no))
Then, complete ID lines of homologs are given preceded by DB names where they were found by BLAST (e.g., NR:) and followed by statistics from corresponding BLAST outputs.
## COG: DRA0007 COG1131 # Protein_GI_number: 15807679 # Func_class: V Defense mechanisms # Function: ABC-type multidrug transport system, ATPase component # Organism: Deinococcus radiodurans # 1 301 1 301 301 503 100.0 1e-142 ## KEGG: DRA0007 # Name: not_defined # Def: putative ABC-2 type transport system ATP-binding protein # Organism: D.radiodurans # Pathway: ABC transporters - General [PATH:dra02010] # 1 301 1 301 301 503 100.0 1e-142 ## NR: gi|6460585|gb|AAF12291.1| ABC transporter, ATP-binding protein, putative [Deinococcus radiodurans R1]^Agi|15807679|ref|NP_285331.1| ABC transporter, ATP-binding protein, putative [Deinococcus radiodurans R1] # 1 301 1 301 301 503 100.0 1e-141
BLAST parameters of similarity found for predicted protein are shown in the following order:
Start and stop of region of similarity ( 1 301) in predicted protein
Start and stop of region of similarity (1 301) in homolog from a database
Length of homologous protein (301)
BLAST score (503) and Identity (100.0 %)
BLAST Expected value (1e-141)
For other predictions (rRNA, promoters, etc.) we provide only description lines, for example:
- LSU_RRNA 884415 - 887254 98.0 # Leuconostoc oenos S60377
rRNAs are labeled as LSU_RRNA, SSU_RRNA or 5S_RRNA (large subunit, small subunit, and 5S), tRNAs as TRNA, promoters as Prom, and terminators as Term.
Terminator regions (their coordinates and scores) are reported by FindTerm program:
+ Term 492 - 537 -0.9
Promoters (their coordinates and scores) are reported by BPROM program.