
![]()
|
|
|
|
BdClust |
Clustering of gene expression profiles or samples by Ben-Dor algorithm.
The expression data for the set of genes is represented as a table, consisting of rows (usually corresponding to genes) and columns (or fields, usually corresponding to samples/tissues/experiments). Each row corresponds to expression measurements for the gene. Columns correspond to experiments/samples/tissues. However, this table may include not only expression data, but also other information related to genes, for example gene names, classifiers, etc. Therefore we will call the table columns as 'fields' in general case. In general, columns of the table could be of four basic types:
| IVALUE | signed integer value; | |
| FVALUE | floating point value; | |
| WORD | text without spaces inside (single word); | |
| STRING | text with spaces inside allowed. |
Basic input file format should be as follows:
; May contain comment starting from the semicolon in any line of the file NAME<tab>WORD GENEID<tab>IVALUE TISSUECANCER0<tab>FVALUE TISSUECANCER1<tab>FVALUE TISSUENORMAL0<tab>FVALUE TISSUENORMAL1<tab>FVALUE TISSUENORMAL2<tab>FVALUE #GROUP<tab>Cancer tissues TISSUECANCER0 TISSUECANCER1 #ENDGROUP #GROUP<tab>Arbitrary group TISSUECANCER1 TISSUECANCER2 TISSUENORMAL0 TISSUENORMAL1 #ENDGROUP END DATA GENE04675<tab>402<tab>6.00<tab>5.60<tab>5.97<tab>6.00<tab>6.00 GENE46890<tab>794<tab>2.77<tab>3.22<tab>5.65<tab>5.68<tab>5.68 GENE23794<tab>404<tab>5.97<tab>5.97<tab>6.00<tab>5.60<tab>5.97
In this example <tab> implies 'Tab' character symbol.
First lines (up to the "DATA" line) contain data format description. In this part of the file each line describes field description: field name and field basic type.
After the "DATA" line - data on each gene are represented. Each line correspond single cards. Field data are separated by 'tab' symbol. Double 'tab' is interpreted as missed data.
It is assumed in SetTag program that the expression data in the file are normalized and the expression levels of genes in experiments are comparable.
MolQuest version of the SelTag program can also operates with other types of files, namely, selection files. These files contain information about some selected genes or samples from the large data file in SelTag format. The selection file contain: the data file name from which selection was obtained; type of selection data (genes of samples), list of selected objects (their indices in the large data file). The selection files are in the XML format. Two examples are below.
Selection for some genes.
<?xml version="1.0" encoding="ISO-8859-5"?> <SELECTION> <HEADER name="cc_Selection5"> <DATA source="c:/data/cc.txt"/> <COMMENT><![CDATA["$F1 == "GEN14263" | $F12 >= 300"]]></COMMENT> </HEADER> <ELEMENTS type="GENES" count="9"> <![CDATA[0;1;2;10;14;15;17;26;30]]> </ELEMENTS> </SELECTION>
Selection for some fields (samples).
<?xml version="1.0" encoding="ISO-8859-5"?> <SELECTION> <HEADER name="notterman2001_set1"> <DATA source="c:/data/notterman2001_set1.txt"/> <COMMENT><![CDATA["From cc.txt data file."]]></COMMENT> </HEADER> <ELEMENTS type="FIELDS" count="10"> <![CDATA[0;1;2;3;5;6;7;18;19;30]]> </ELEMENTS> </SELECTION>
Selection files may be selected during the SelTag execution and also used by SelTag for calculation and/or visualization. Note, each selection file is linked to large data file by its name. Selection data cannot be applied to another data file.
The program allows clustering genes by their expression profile similarity. The purpose of the analysis is to select groups of genes that have common patterns of expression in different experiments, e.g. high expression in cancer tissues and low expression in normal tissues. These patterns of co-expression are usually treated as co-regulation. The similarity of the expressions patterns may not be limited by simple rules and can be described by similarity (or distance) Measures. There are several measures of expression profile similarity between two genes:
(1) Euclidean distance. This is the geometric distance in the multidimensional space.
It is computed as:
![]()
where xi, xj are two expression profiles for genes i,j,k is the index
of experiment (field), xik is the expression value of gene i in the experiment k.
(2) Squared Euclidean distance. The squared Euclidean distance can be
implemented in order to place progressively greater weight on objects that
are further apart. The squared Euclidian distance is computed as:
![]()
(see explanation above). The Euclidian and squared Euclidian distances are computed
from raw data (non-standardized), therefore they may be affected by differences in
scale among the expression values in different experiments.
(3) Manhattan distance. This distance is the average absolute difference for the set of experiments calculated by the formula
![]() .
.
In most cases, this distance measure yields results similar to the simple Euclidean distance, for this measure, the effect
of single large differences is dampened (since they are not squared).
(4) Chebychev distance. This distance is computed as dij = maxk | xik - xik |. The measure is useful when one wants to define two objects as "different" if they are different on any one of the experiments.
In SelTag all distance measures (1-3) are normalized to the number of fields involved in calculation. This is useful when take into account expression data with missing values.
Other measures involve correlation coefficient rij between two expression profiles of genes i and j.
(5) 1-rij; This measure keep close profiles with positive correlation coefficients and is useful when one wants to detect co-regulated genes.
(6) 1-|rij|; This measure keep close profiles with higher absolute value of correlation coefficients.
(7) 1+rij; This measure keep close profiles with negative value of correlation coefficients (anti-correlated).
Three types of correlation are possible for correlation distance option:
Pearson's r - Pearson's correlation coefficient.
The Pearson product moment correlation coefficient between expression profiles i and j is calculated as follows:
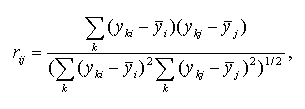
where yki is the expression level of gene i in the experiment k;
![]() is the mean
expression level of the gene i. Positive correlation implies that the
expression levels of genes i,j are related positively, the higher expression
of gene i, the higher expression of gene j. Negative correlation
means that the expression levels of genes i,j are related negatively, the
higher expression of gene i, the lower expression of gene j.
If the rij is close to zero, two expression profiles are unrelated.
is the mean
expression level of the gene i. Positive correlation implies that the
expression levels of genes i,j are related positively, the higher expression
of gene i, the higher expression of gene j. Negative correlation
means that the expression levels of genes i,j are related negatively, the
higher expression of gene i, the lower expression of gene j.
If the rij is close to zero, two expression profiles are unrelated.
Spearman r - Spearman's correlation coefficient.
This correlation coefficient is computed for ranks. Let Rki is
the rank of the expression level in the experiment k of gene i
(relatively to other experiments), Rkj is the rank of the
expression level in the experiment k of gene j.
Then Spearman's correlation coefficient is calculated by the formula
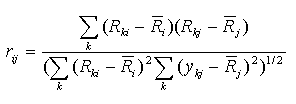
Kendall's t - Kendall's tau correlation coefficient.
To calculate Kendall's t K for data points
(yki; ykj) 2K(K - 1) pairs considered (without self-pairing, the points
in either order count as one pair).
Pairs in which yki > ymi and
ykj > ymj or
yki < ymi and ykj < ymj
are called concordant pairs (agreement between ranks), pairs with rank disagreement are called discordant pairs.
In general, t is calculated as
t = ([number of concordant] - [number of discordant]) / total number of pairs
The program implements Cluster Affinity Search Technique (CAST), proposed by Ben-Dor et al [Ben-Dor A., Shamir R., Yakhini Z. (1999) J. Comput. Biol. 6, 281-297].
A common shortcoming of hierarchical clustering techniques, such as single-linkage, complete-linkage, group-average, and centroid, is due to their "greedy" nature, once a decision to join two elements in one cluster is made, it cannot be undone. The CAST algorithm use the "affinity" values to perform "cleaning" step while making clusters by removing low-affinity elements of the cluster. The affinity in the CAST algorithm is the average similarity between gene expression profile and gene profiles already included to the cluster. The threshold for affinity is user-defined.
status=Correlation matrix calculation... status=CAST clustering... status=done [0.0 sec] Number of gene clusters obtained 4. Cluster Sizes and Scores: Cluster 1 2 1.7469 Cluster 2 10 1.6321 Cluster 3 7 1.7248 Cluster 4 4 1.6679 List of selected genes, their cluster indices and scores : No DataIndex Name Cluster Score 1 1 GEN30482 2 1.6892 2 2 GEN03437 2 1.6962 3 3 GEN03687 2 1.6649 4 4 GEN24649 2 1.6463
Some lines starting from "status=" are just output the status of the calculation and can be ignored. Then the result cluster information is output: number of clusters, their list with cluster scores. Then list of selected genes with their cluster indices and scores is printed out.